1) Choose The Huggingface LLama3 TGI API Template From the Recommended Section
Login to your Vast account on the console Select the HuggingFace Llama3 TGI API template by clicking the link provider For this template we will be using the meta-llama/Meta-Llama-3-8B-Instruct model, and the TGI 2.0.4 from Huggingface Templates encapsulate all the information required to run an application on Vast Serverless, including machine parameters, docker image, and environment variables. For this template, the only requirement is that you have your own Huggingface access token. You will also need to apply to have access to Llama3 on huggingface in order to access this gated repository. The template comes with some filters that are minimum requirements for TGI to run effectively. This includes but is not limited to a disk space requirement of 100GB, and a gpu ram requirement of at least 16GB. After selecting the template your screen should look like this: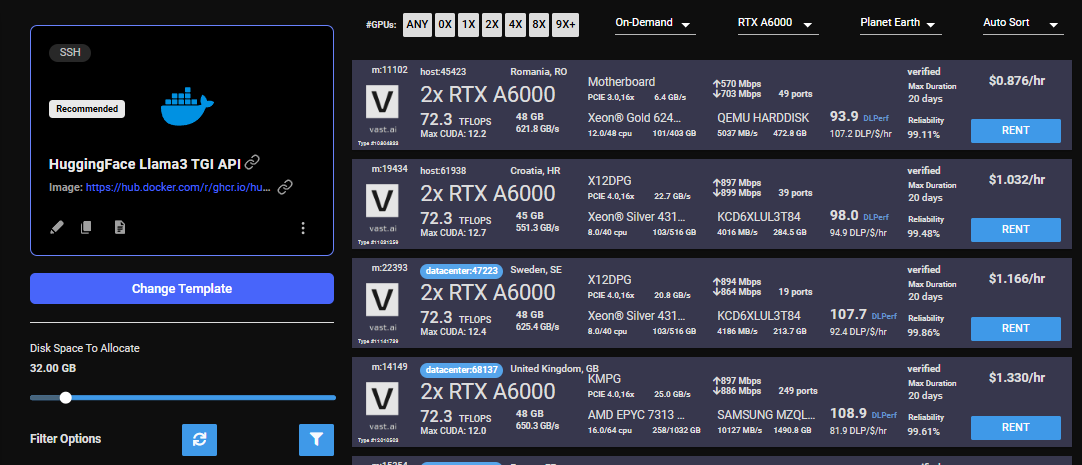
Select
2) Modifying the Template
Once you have selected the template, you will need to then add in your huggingface token and click the ‘Select & Save’ button. You can add your huggingface token with the rest of the docker run options.

Edithf
3) Rent a GPU
Once you have selected the template, you can then choose to rent a GPU of your choice from either the search page or the CLI/API. For someone just getting started I recommend either an Nvidia RTX 4090, or an A5000.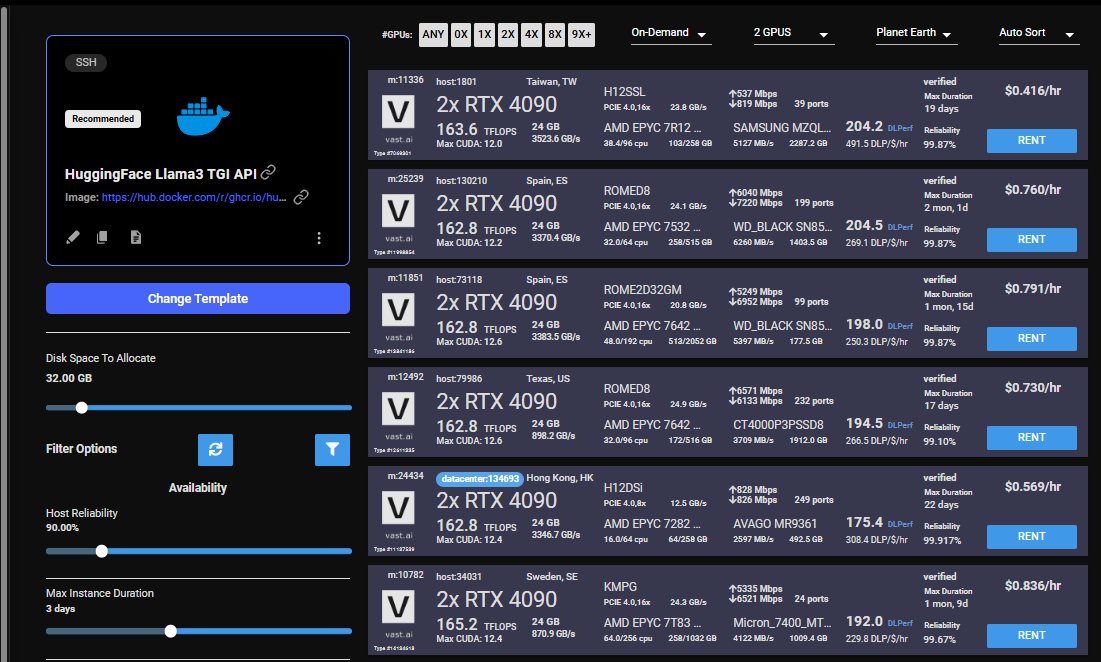
Rent
4) Monitor Your Instance
Once you rent a GPU your instance will being spinning up on the Instances page. You know the API will be ready when your instance looks like this:
Llama3Tgiinstances
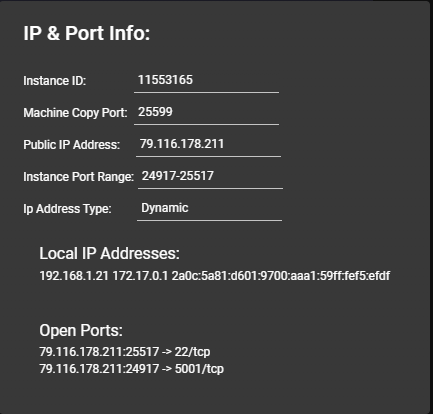
Llama3Ip
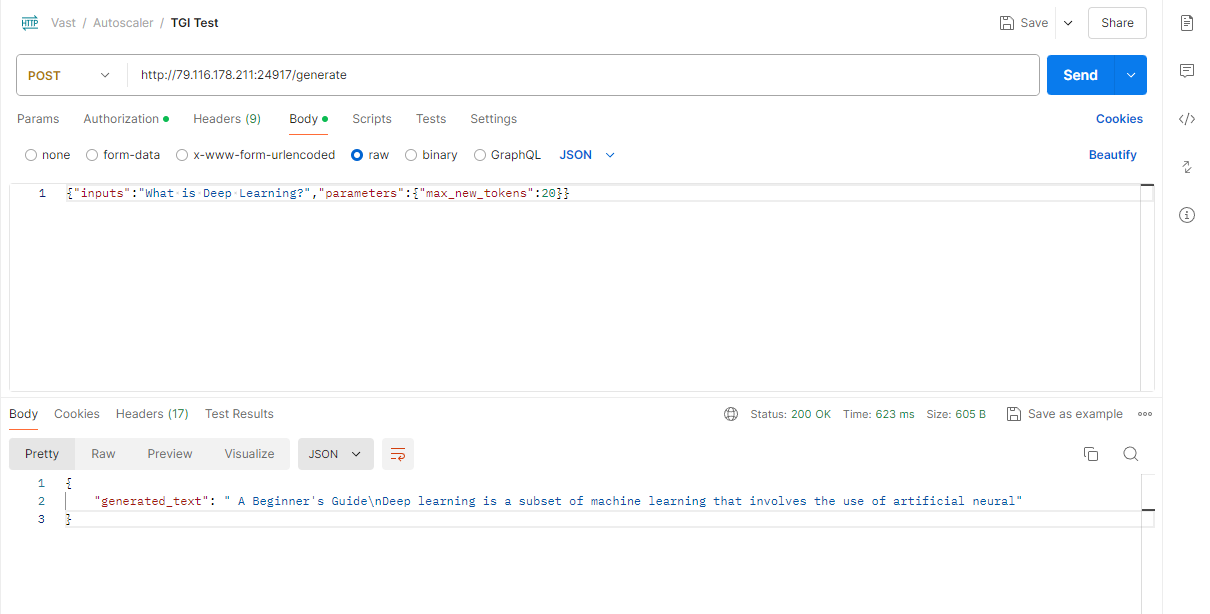
Llama3Tgipostman