1) Setup your Vast account
The first thing to do if you are new to Vast is to create an account and verify your email address. Then head to the Billing tab and add credits. Vast uses Stripe to processes credit card payments and also accepts major cryptocurrencies through BitPay or Crypto.com. $20 should be enough to start. You can setup auto-top ups so that your credit card is charged when your balance is low.2) Pick the Oobabooga template
Go to the Templates tab and search for “Oobabooga” among recommended templates and select it.3) Allocate storage
The default storage amount will not be enough for downloading an LLM. Use the slider under the Instance Configuration to allocate more storage. 100GB should be enough.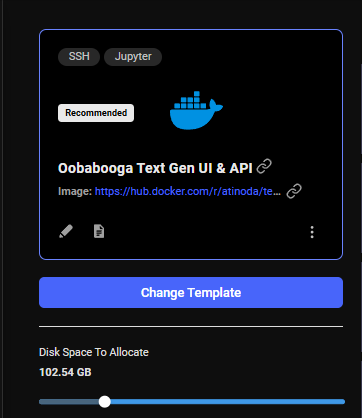
Ooobaboogasize
4) Pick a GPU offer
You will need to understand how much GPU RAM the LLM requires before you pick a GPU. For example, the Falcon 40B Instruct model requires 85-100 GB of GPU RAM. Falcon 7B only requires 16GB. Other models do not have great documentation on how much GPU RAM they require. If the instance doesn’t have enough GPU RAM, there will be an error when trying to load the model. You can use multiple GPUs in a single instance and add their GPU RAM together. For this guide, we will load the Falcon 40B Instruct model on a 2X A6000 instance, which has 96GB of GPU RAM in total.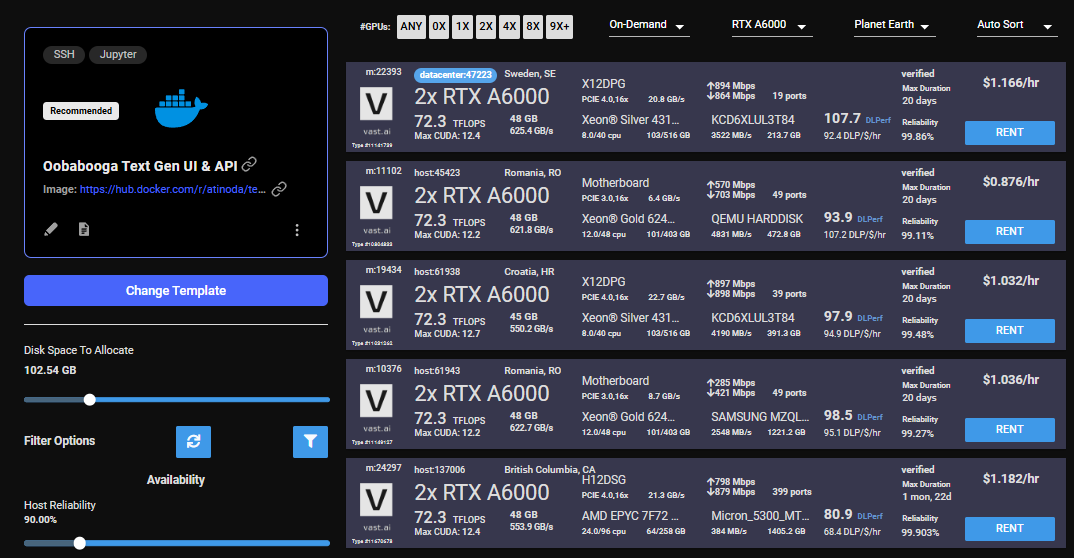
Oobabooga search
5) Open Oobabooga
Once the instance boots up, the Open button will open port 7860 in a new browser window. This is the Oobabooga web interface. The web gui can take an additional 1-2 minutes to load. If the button is stuck on “Connecting” for more than 10 minutes, then something has gone wrong. You can check the log for an error and/or contact us on website chat support for 24/7 help.6) Download the LLM
Click on the Model tab in the interface. Enter the Hugging Face username/model path, for instance: tiiuae/falcon-40b-instruct. To specify a branch, add it at the end after a ”:” character like this: tiiuae/falcon-40b-instruct The download will take 15-20 minutes depending on the machine’s internet connection.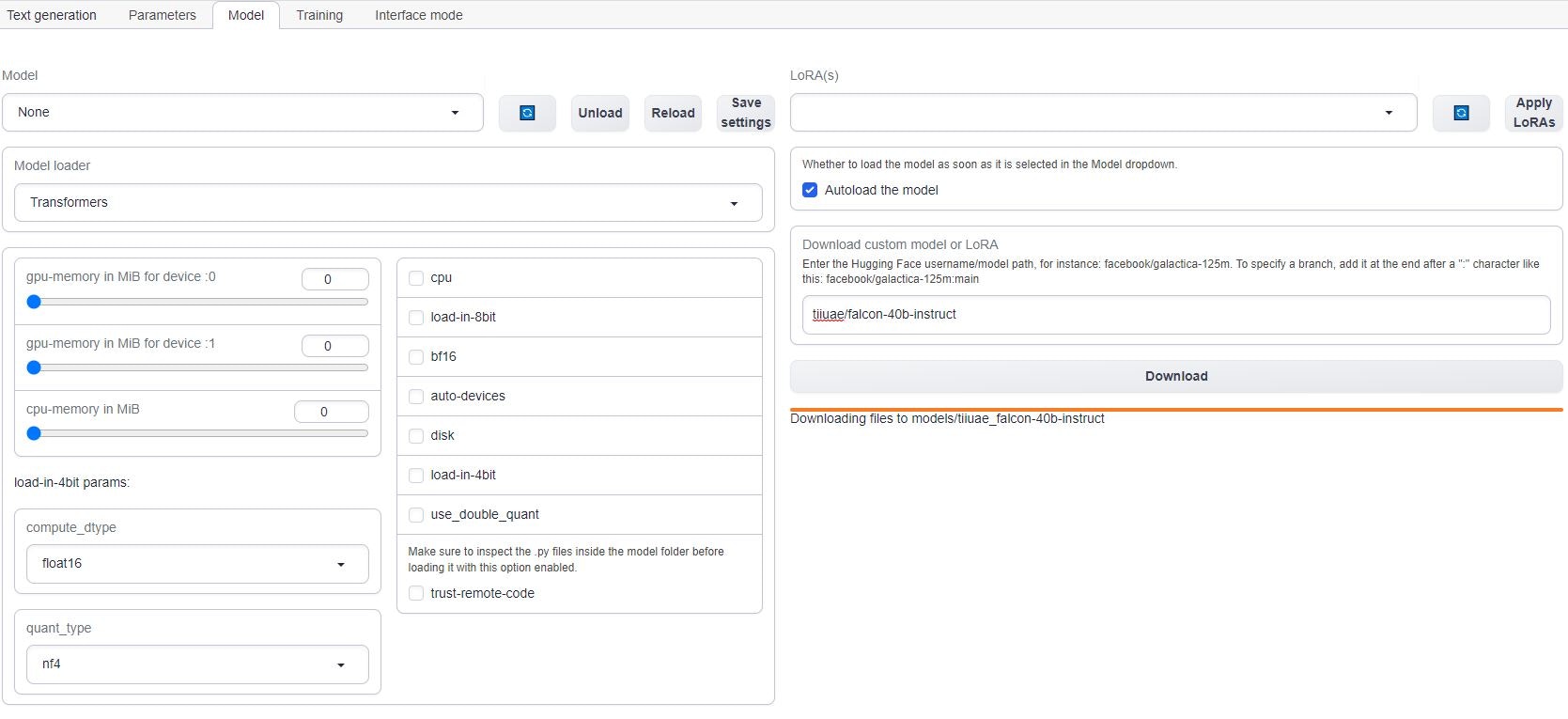
Oob Downloading
7) Load the LLM
If you are using multiple GPUs such as the 2X A6000 selected in this guide, you will need to move the memory slider all the way over for all the GPUs. You may also have to select the “trust-remote-code” option if you get that error. Once those items are fixed, you can reload the model.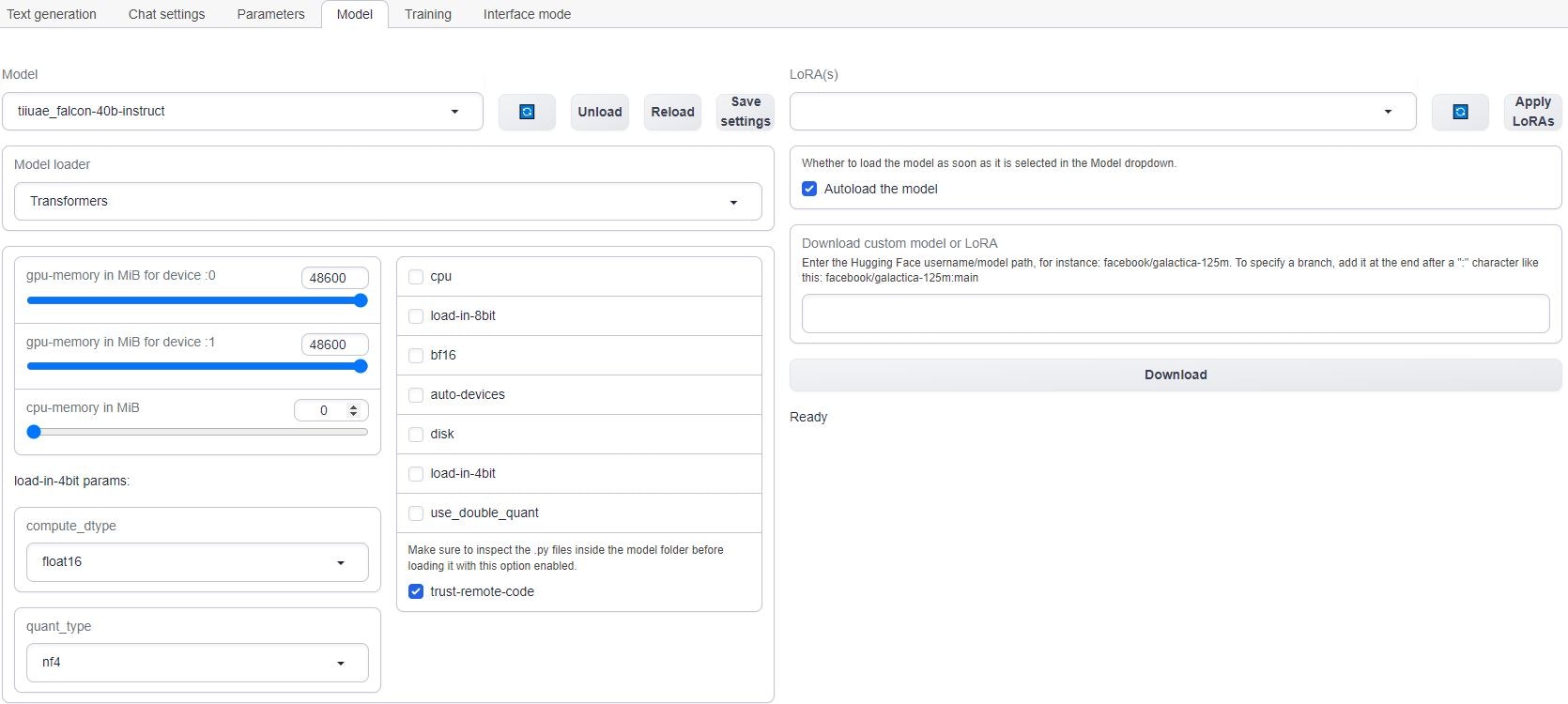
Oob Model Load