The Vast.ai Serverless architecture is a multi-component system that manages GPU-backed workers to efficiently serve applications. It automatically scales up or down based on endpoint parameters, workergroup parameters, and measured load reported by workers.Documentation Index
Fetch the complete documentation index at: https://docs.vast.ai/llms.txt
Use this file to discover all available pages before exploring further.
Primary Components
Endpoints
An Endpoint is the highest-level construct in Vast Serverless. Endpoints are configured with endpoint-level parameters that control scaling behavior, capacity limits, and utilization targets. An endpoint consists of:- A named endpoint identifier
- Typically one workergroup
- Endpoint parameters such as
max_workers,min_load,min_workers,cold_mult,min_cold_load,target_util,inactivity_timeout,max_queue_time, andtarget_queue_time
Workergroups
A Workergroup defines what code runs on the endpoint (via the template), as well as how workers are recruited and created. Workergroups are configured with workergroup-level parameters and are responsible for selecting which GPU offers are eligible for worker creation. Each Workergroup includes:- A serverless-compatible template (referenced by
template_idortemplate_hash) - Hardware and marketplace filters defined via
search_params - Optional instance configuration overrides via
launch_args - Hardware requirements such as
gpu_ram - A set of GPU instances (workers) created from the template
Workers
Workers are individual GPU instances created and managed by the Serverless engine. Each worker runs a PyWorker, a Python web server that monitors the inference server’s readiness, proxies incoming requests, and coordinates with the autoscaler. Workers can exist in active or inactive states and are responsible for:- Receiving and processing inference requests
- Reporting performance metrics (load, utilization, benchmark results)
- Informing automated scaling and routing decisions
Serverless Engine
The Serverless Engine is the decision-making service that routes incoming requests and manages workers across all endpoints and workergroups. Using configuration parameters and real-time metrics, it determines when to:- Recruit new workers
- Activate inactive workers
- Release or destroy workers
SDK
The Serverless SDK is the primary interface for interacting with Vast Serverless. It is a Pythonpip package that abstracts low-level details and manages:
- Authentication
- Request queuing, retries, and error handling
- Asynchronous request management
- Worker status and lifecycle information
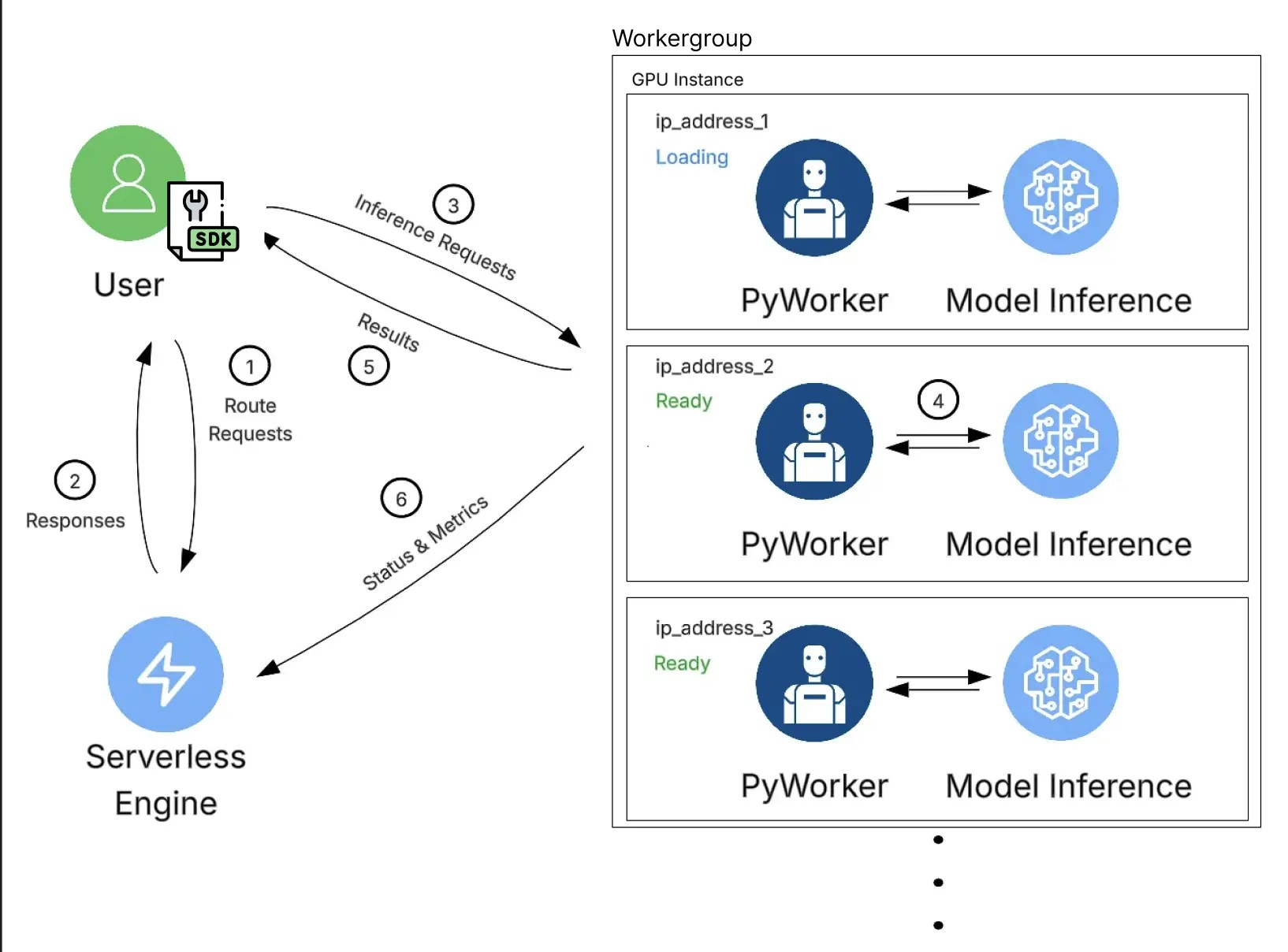
Example Workflow
- The client application sends a request using the Serverless SDK.
- The Serverless system routes the request and returns a suitable worker address based on current load and capacity.
- The client sends the request directly to the selected worker’s API endpoint, including the required authentication data.
- The PyWorker running on the GPU instance forwards the request to the machine learning model and performs inference.
- The inference result is returned to the client application.
- Independently and continuously, each PyWorker reports operational and performance metrics back to the Serverless Engine, which uses this data to make ongoing scaling decisions.