Vast has pre-made templates with PyWorkers already built-in. Search the templates section first to see if a supported template works for your use case.
workers/hello_world/ PyWorker is created for an LLM server with two API endpoints:
/generate: generates a LLM response and sends a JSON response/generate_stream: streams a response one token at a time
JSON
Structure
All PyWorkers have four files:Text
pyright plugin to find any type errors in your implementation. You can also install pyright with npm install pyright and run pyright in the root of the project to find any type errors.
__init__.py
The__init__.pyfile is left blank. This tells the Python interpreter to treat the hello_world directory as a package. This allows us to import modules from within the directory.
data_types.py
This file defines how the PyWorker interacts with the ML model, and must adhere to the common framework laid out inlib/data_types.py. The file implements the specific request structure and payload handling that will be used in server.py.
Data handling classes must inherit from lib.data_types.ApiPayload. ApiPayload is an abstract class that needs several functions defined for it. Below is an example implementation from the hello_world PyWorker that shows how to use the ApiPayload class.
Python
server.py
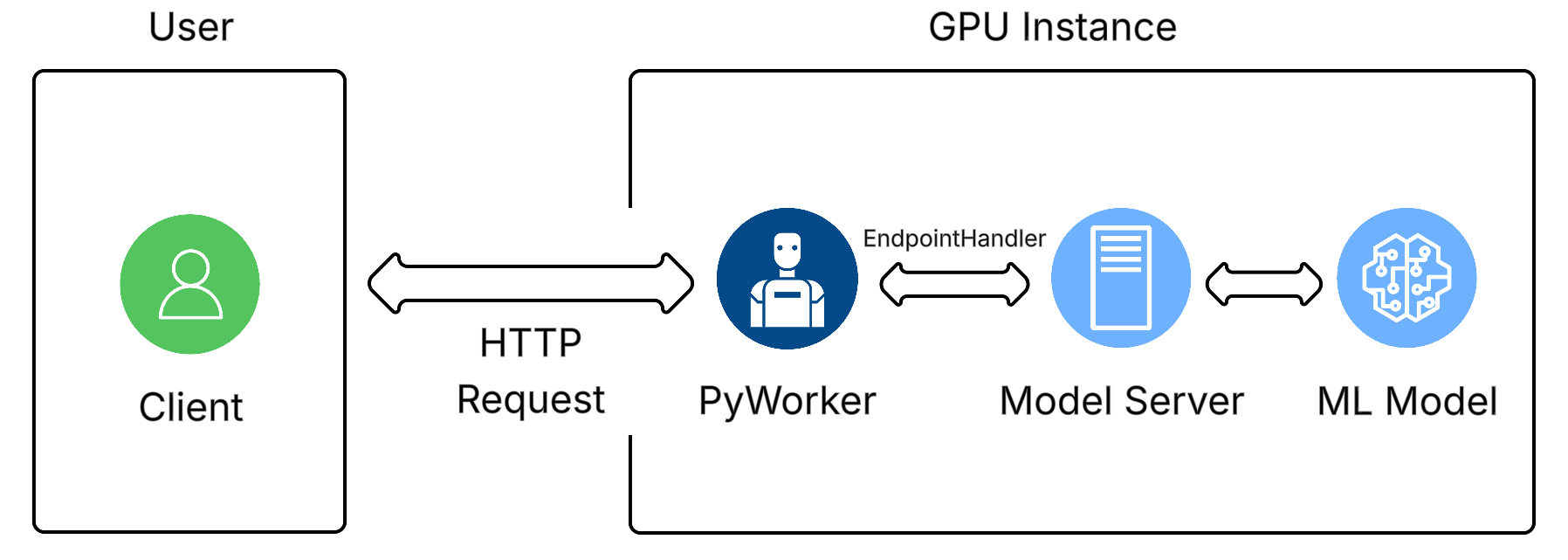
For every ML model API endpoint you want to use, you must implement anEndpointHandler. This class handles incoming requests, processes them, sends them to the model API server, and finally returns an HTTP response with the model’s results. EndpointHandler has several abstract functions that must be implemented. Here, we implement the /generate endpoint functionality for the PyWorker by creating the GenerateHandler class that inherits from EndpointHandler.
Python
GenerateStreamHandler for streaming responses. It is identical to GenerateHandler, except that this implementation creates a web response:
Python
Python
server.py implementation of the hello_world PyWorker, as shown here:
Python
test_load.py
Once a Serverless Endpoint is setup with a {{Worker_Group}}, thetest_load module lets us test the running instances:
Python
- -n is the total number of requests to be send to the Endpoint
- -rps is the rate (rate per second) at which the requests will be sent
- -k is your Vast API key. You can define it in your environment or paste it into the command
- -e is the name of the Serverless Endpoint
Text

These are all the parts of a PyWorker! You will also find a client.py module in the worker folders of the repo. While it is not part of the PyWorker, Vast provides it as an example of how a user could interact with their model on the serverless system. The client.py file is not needed for the PyWorker to run on a GPU instance, and is intended to run on your local machine. The PyWorker Overview page shows more details.