- The core ML model.
- The model server code that handles requests and inferences the ML model.
- The PyWorker server code that wraps the ML model, which formats incoming HTTP requests into a compatible format for the model server.
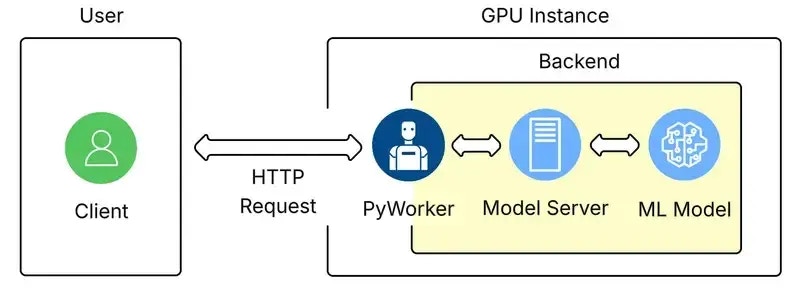
Backend Configuration
Once a User has connected to a GPU Instance over Vast, the backend will start its own launch script. The launch script will:- Setup a log file.
- Start a webserver to communicate with the ML model and PyWorker.
- Set environment variables.
- Launch the PyWorker and create a directory for it.
- Monitor the webserver and PyWorker processes.
Adding Endpoints
To add an endpoint to an existing backend, follow the instructions in the PyWorker Extension Guide. This guide can also be used to write new backends.Authentication
The authentication information returned by https://run.vast.ai/route/ must be included in the request JSON to the PyWorker, but will be filtered out before forwarding to the model server. For example, a PyWorker expects to receive auth data in the request:JSON
JSON
/route/ endpoint, it provides a unique signature with your request. The authentication server verifies this signature to ensure that only authorized clients can send requests to your server.