- Instance<->Instance and Instance<->Local copy using the
vastai copyCLI command - Instance<->Instance copy in the GUI instance control panel or
vastai copyCLI command - Cloud Sync using the GUI instance control panel or
vastai cloud copyCLI command
- Instance<->Instance migration through the
vastai copyCLI command or the GUI instance control panel
Cloud Sync
The Cloud Sync feature allows you to copy data to/from instance local storage and several cloud storage providers (S3, gdrive, backblaze, etc) - even when the instance is stopped.Using the GUI
Vast currently supports Dropbox, Amazon S3 and Backblaze cloud storage providers. First you will need to connect to the cloud provider on the account page and then use the cloud copy button on the instance to start the copy operation.
Using the CLI
You can also access this feature using thevastai cloud copy CLI command.
Instance <-> Instance copy
Instance to instance copy allows moving data directly between the local storage of two instances. If the two instances are on the same machine or the same local network (same provider and location) then the copy can run at faster local network storage speeds and there is no internet transit cost.Using the GUI
You can use the copy buttons to copy data between two instances. Instances can be stopped/inactive. See complete Constraints below. Click the copy button on the source instance and then on the destination instance to bring up the copy dialogue. For docker-based instances you will see the following folder dialogue.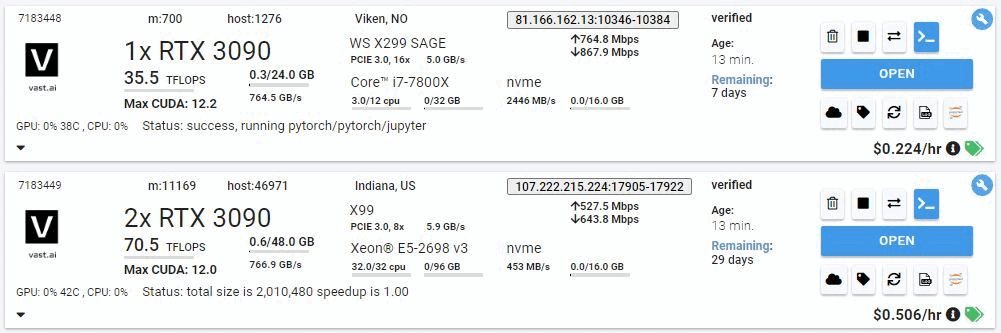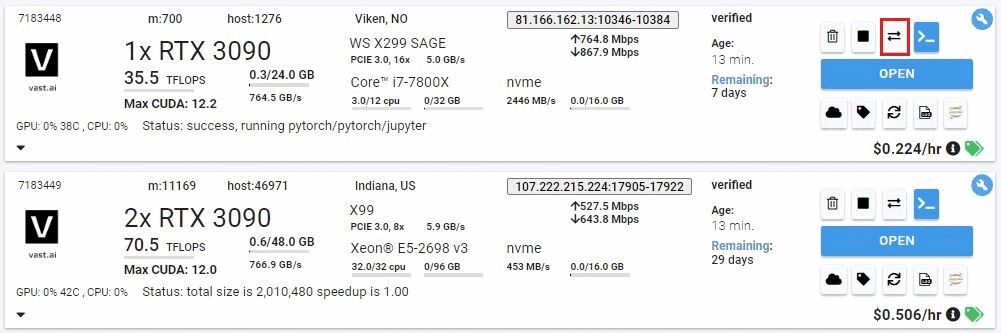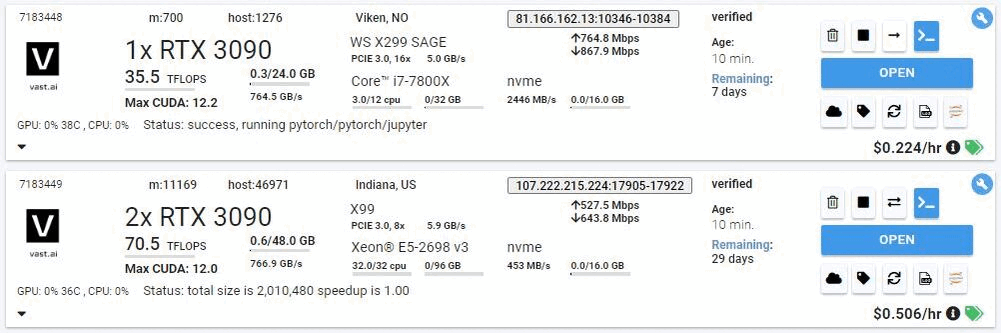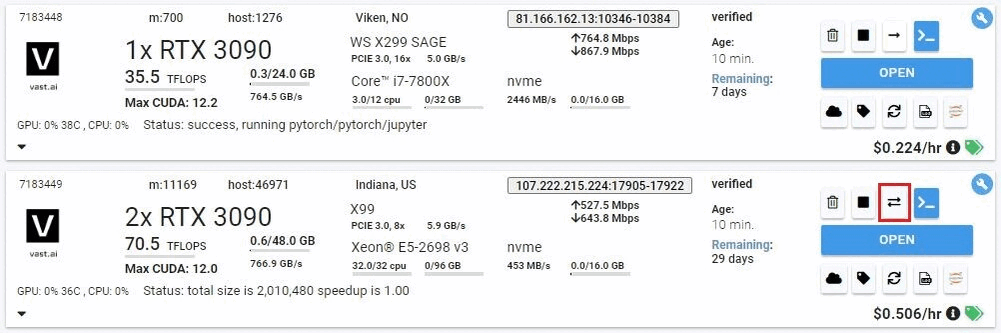
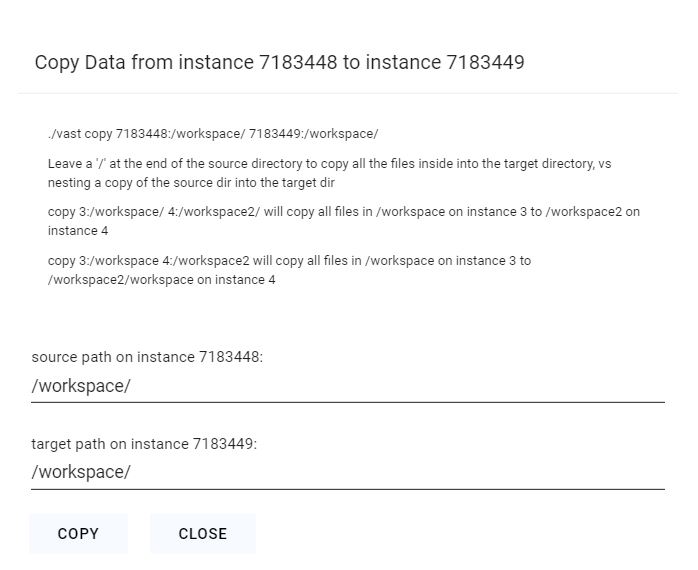
Using the CLI
You can also access this feature using thevastai copy CLI command.
CLI Copy Command
You can use the CLI copy command to copy from/to directories on a remote instance and your local machine, or to copy data between two remote instances. The copy command uses rsync and is generally fast and efficient, subject to single link upload/download constraints. The copy command supports multiple location formats:[instance_id:]path- Legacy format (still supported)C.instance_id:path- Container copy formatcloud_service:path- Cloud service formatcloud_service.cloud_service_id:path- Cloud service with IDlocal:path- Explicit local path
Text
CLI Copy Command (VMs)
For VM instances, use the standardvastai copy command with two instance IDs. This performs a full-disk migration: the destination VM’s disk is completely replaced with the contents of the source machine. No subpaths or individual folder selection is supported.
vastai vm copy is not available as a CLI command. Use vastai copy instead.Text
Constraints
- The destination instance must be stopped during the transfer.
- Only full-disk copies are supported, subpaths and individual folder copies are not available for VMs.
- Copy is only supported between two VM instances, not to/from cloud storage.
Performance
If your data is already stored in the cloud (S3, gdrive, etc) then you should naturally use the appropriate linux CLI or commands to download and upload data directly, or you could use the Cloud Sync feature. This generally will be one the fastest methods for moving large quantities of data, as it can fully saturate a large number of download links. If you are using multiple instances with significant data movement requirements you will want to use high bandwidth cloud storage to avoid any single machine bottlenecks. If you launched a Jupyter notebook instance, you can use its upload feature, but this has a file size limit and can be slow. You can also use standard Linux tools like scp, ftp, rclone, or rsync to move data. For moving code and smaller files scp is fast enough and convenient. However, be warned that the default ssh connection uses a proxy and can be slow for large transfers (direct ssh recommended). Instance to instance copy is generally as fast as other methods, and can be much faster (and cheaper) for moving data between instances on the same datacenter.SCP
If you launched an ssh instance, you can copy files using scp. The proxy ssh connection can be slow (in terms of latency and bandwidth). Thus we recommend only using scp over the proxy ssh connection for smaller transfers (less than 1 GB). For larger inbound transfers, using the direct ssh connection is recommended. Downloading from a cloud data store using wget or curl can have much higher performance. The relevant scp command syntax is:Text
Text
Text
Text
Common Questions
How do you recommend I move data from an existing instance?
The Cloud Sync feature will allow you to move data to and from instances easily. The main benefit is that you can move data around while the machine is inactive. Currently, we support Google Drive, S3, Dropbox, and BackblazeHelp, I want to move my data but I forgot what directory it’s in!
For moving your data, by either using our Cloud Sync or Instance Copy features, you will need to define the path from where the data you are transferring is coming from and where it is to be put. If you don’t remember where the data is you are trying to transfer, you can use our CLI execute command to access your instance when your instance access is limited.What if I don’t remember the file names on my inactive instance, but I want to copy certain files?
Use the vast CLI, run theexecute command to display the file tree. This will help you browse the available files and identify the names or paths you need. More about the execute command you can find here.